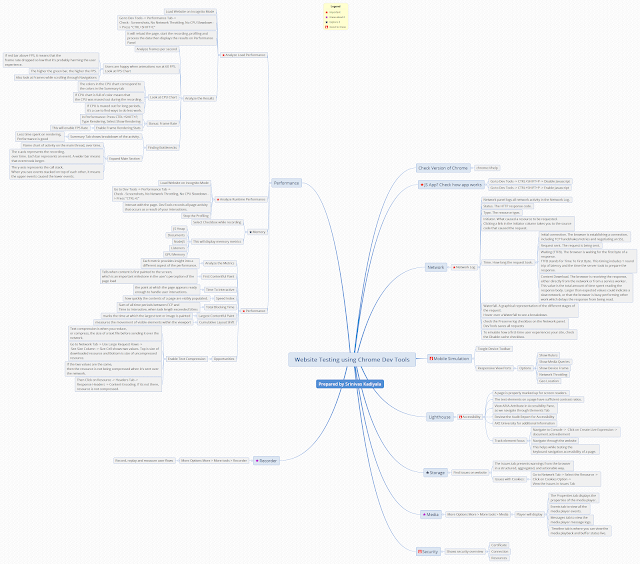
Why would websites have robots.txt ?
Few days ago, a new concept came landed on my desk - ROBOTS.TXT and I haven't heard about it before. I have asked many of my friends/colleagues.

Thanks to my guide - Thomas, who gave me a clear thoughts about robots.txt. Here is my learning notes from it.
Web Robots (also known as Web Wanderers, Crawlers, or Spiders), are programs that traverse the Web automatically. Web site owners use the /robots.txt - text file to give instructions about their site to web robots; this is called The Robots Exclusion Protocol.
This file is placed on web server under root folder and advises spiders and other robots which directories or files they should/ should not access.
Example: www.yourwebsite.com/robots.txt
What does it do exactly?When a keyword is searched, first thing web spiders visits is robots.txt file. It looks in the file to know what it should do - based on the instructions mentioned in robots.txt
Why robots.txt file?
1. Most people want robots to visit all the web pages and content in their website.
How to make this work?1. Don't have robots.txt file in the web server2. Add empty robots.txt file without any instructions3. Add robots.txt file with the following instructions:User-agent: *Disallow:Here, * - means any web robots.
Disallow - tells the robots what folders they should not look at in website.* List of various web robots: www.robotstxt.org/db.html
2. Few people want robots to restrict some files in the web server and few files allows to visit.User-agent: * Disallow: /checkoutAllow: /imagesThe "Allow:" instructions tells web robot, that it is okay to see a files in images folder.
How to test robots.txt file?
1. We can test robots.txt with the Google Webmaster tool - robots.txt Tester2. To find out if an individual page is blocked by robots.txt you can use this online tool which will tell you if a page is blocked or not.